Disaster Recovery
This guide explains how to set up disaster recovery for ReductStore to ensure data resilience and availability. It covers the following types of disasters:
- Hardware Failure: Physical damage to the server or storage devices.
- Data Corruption: Logical errors that lead to data being unreadable or inconsistent.
- Network Outage: Loss of connectivity that prevents access to the ReductStore instance.
- Operational Errors: Mistakes made by users or administrators that lead to data loss or corruption.
ReductStore provides several strategies to mitigate these risks which will be described in this guide. In the table below, you can see the available strategies and their effectiveness against different types of disasters.
| Disaster Recovery Strategy | Description | Downtime | Hardware Failure | Data Corruption | Network Outage | Operational Errors |
|---|---|---|---|---|---|---|
| Data Loss Detection and Automated Recovery | Mechanisms to detect data loss and recover automatically to keep an instance working | seconds | ✅ (limited) | ✅ (limited) | ❌ | ❌ |
| Cold Backup via File System | Copying data as files | minutes/hours | ✅ | ✅ | ❌ | ✅ |
| Hot Backup via CLI | Copying data with ReductStore CLI to a backup instance | zero | ✅ | ✅ | ❌ | ✅ |
| Hot Standby Setup | Active-passive pair sharing the same storage with a lock file | seconds | ✅ | ❌ | ✅ | ❌ |
| Read-only Replicas | One writer with multiple read-only nodes for read scaling and decoupled ingestion | zero | ✅ | ❌ | ✅ | ❌ |
Data Loss Detection and Automated Recovery
ReductStore’s disaster recovery strategy begins with detecting data loss. The core principle is: whatever happens, detect and isolate the problem as early as possible, and continue operating with unaffected data.
Detection and isolation are based on the internal storage structure and format, which you can learn more about in the How Does It Work section. These mechanisms operate during both instance startup and I/O operations.
Startup Data Loss Detection
When a ReductStore instance starts, the storage engine performs the following checks:
- Verifies and replays Write-Ahead Logs (WALs)
- Updates indexes
- Validates data integrity
For S3 backends, these integrity checks can take time and incur additional S3 request costs. You can disable them with RS_ENGINE_ENABLE_INTEGRITY_CHECKS=false.
This process helps recover from the following scenarios:
- Power Failure or Crash:
- If ReductStore was not shut down properly, the engine detects incomplete WALs and restores the data to the last consistent state.
- File System Corruption:
- Each index file has a CRC to verify its integrity. If corrupted, the engine will detect this and recreate it from block descriptors.
- If the number or size of data blocks doesn’t match the index file, it will be rebuilt using the block descriptors.
- If the storage engine detects a corrupted block descriptor during the index rebuild, it will remove the corrupted block and continue with the rest of the data (when integrity checks are enabled).
Runtime Data Loss Detection
During I/O operations, ReductStore checks the integrity of block descriptors. If corruption is detected:
- The storage engine aborts the current I/O operation.
- A
500 Internal Server Erroris returned. - The issue is logged for administrative review.
- The corrupted block is removed from the in-memory index and will be ignored on subsequent requests until restart. On restart, the corrupted block is removed only if integrity checks are enabled; otherwise, it must be removed manually or the issue will repeat.
An administrator can inspect the logs and take corrective actions such as removing the corrupted block or restoring it from a backup.
Not every I/O operation will trigger a check. The checks are performed when a block descriptor is read from disk to an in-memory cache.
Content Integrity
The detection mechanisms described above ensure the integrity of metadata and block descriptors—essential for the reliable functioning of the storage engine.
However, they do not verify the actual content of stored records, to avoid performance penalties. To ensure content-level integrity, users can implement their own checksum or hash validation and attach them as labels to records:
md5_hash = md5(data).hexdigest()
ts = time.time()
await bucket.write(
"entry_name",
data,
timestamp=ts,
labels={
"md5": md5_hash,
},
)
Cold Backup via File System
A robust backup and restore strategy is essential for disaster recovery—especially in scenarios involving data corruption or loss. This strategy includes creating regular file backups of the ReductStore instance and restoring them when necessary.
Due to architectural constraints of the ReductStore storage engine, file backups can only be created or restored when the active instance is stopped. This ensures data consistency by preventing write operations during the process but also introduces downtime.
Backup Process
Backups are performed by copying the entire ReductStore data directory (RS_DATA_PATH), which contains all data and configuration files necessary for recovery.
To create a backup:
- Shut down the ReductStore instance to ensure data consistency.
- Copy the entire
RS_DATA_PATHdirectory to your backup location. - Restart the ReductStore instance after the backup is complete.
Backup Verification
It is highly recommended to verify each backup to ensure it can be restored successfully. To test a backup:
- Copy the backup to a new directory.
- Start a new ReductStore instance with the copied data:
RS_DATA_PATH=/path/to/backup reductstore - Check the logs for any startup errors.
- Verify data accessibility, for example:
curl http://127.0.0.1:8383/api/v1/list
Restore Process
Restoring from a backup involves copying data from a backup directory into the ReductStore data directory. Restoration can be done fully or partially, depending on your recovery requirements:
- Full Restore: Restores the entire instance, including all buckets, replication tasks, and configurations.
- Bucket Restore: Restores a specific bucket.
- Entry Restore: Restores a specific entry within a bucket.
ReductStore must be stopped before performing any restore operation.
Full Restore
To perform a full restore, follow these steps:
- Stop the ReductStore instance.
- Remove the current data directory or rename it for backup.
- Copy the backup data directory to the original ReductStore data directory.
- Start the ReductStore instance.
Bucket Restore
To restore a specific bucket, follow these steps:
- Stop the ReductStore instance.
- Remove the bucket directory from the current data directory. It is located at
RS_DATA_PATH/<bucket_name>. - Copy the backup bucket directory to the original ReductStore data directory.
- Start the ReductStore instance.
Entry Restore
To restore a specific entry within a bucket, follow these steps:
- Stop the ReductStore instance.
- Remove the entry file from the current bucket directory. It is located at
RS_DATA_PATH/<bucket_name>/<entry_name>. - Copy the backup entry file to the original bucket directory.
- Start the ReductStore instance.
Hot Backup via CLI
The hot backup strategy uses the ReductStore CLI to copy data from a live instance to a secondary (backup) instance. This method allows you to back up data without stopping the ReductStore instance, minimizing downtime.
While this approach offers more flexibility and control—such as specifying time ranges for incremental backups—it does not copy instance configuration (e.g., bucket definitions, replication rules, etc.).
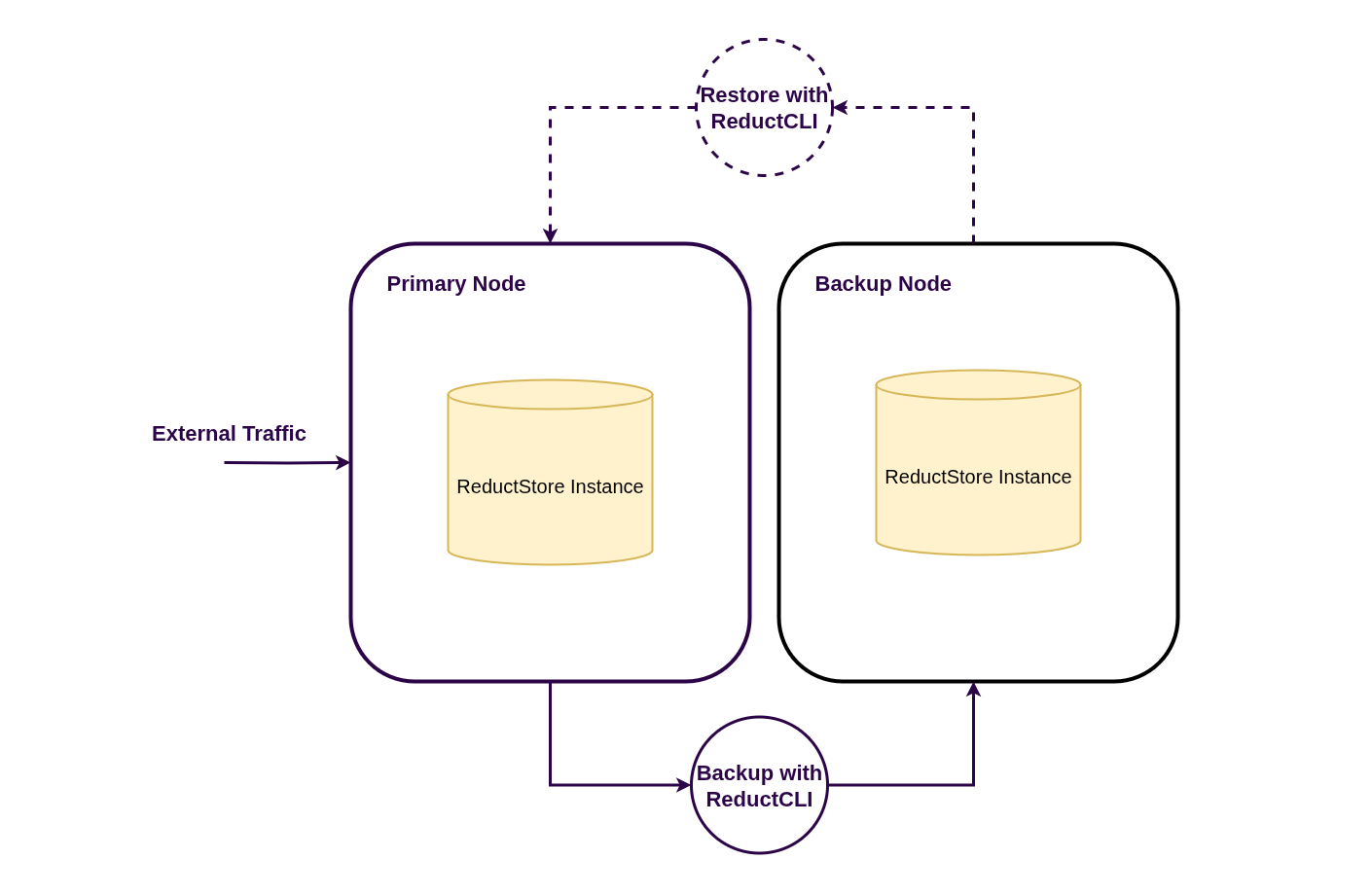
This method is a good option for:
- Incremental backups based on time ranges
- Automated, scheduled backups
Prerequisites
To use this strategy:
- Install the ReductStore CLI (see Download Documentation)
- Create aliases for both your primary and backup instances:
reduct-cli alias add primary -L <URL of the primary instance> --token <API token>
reduct-cli alias add backup -L <URL of the backup instance> --token <API token>
Backup Process
To copy data from a bucket on the primary instance to the backup instance, use the cp command:
reduct-cli cp primary/<bucket_name> backup/<bucket_name> \
--start <OPTIONAL start timestamp> \
--stop <OPTIONAL end timestamp>
If you need to back up all buckets from the latest backup data, you can use this more convenient command:
reduct-cli cp primary/* backup --from-last
These commands support copying a full bucket or all buckets, as well as limiting the copy to a specific time range for incremental or scheduled backups.
Restore Process
To restore a bucket from the backup instance to the primary instance, run the cp command in reverse:
reduct-cli cp backup/<bucket_name> primary/<bucket_name> \
--start <OPTIONAL start timestamp> \
--stop <OPTIONAL end timestamp>
Hot Standby Setup
A hot standby setup runs two ReductStore instances against the same storage backend (shared file system or the same remote backend). Only one instance is allowed to be active at a time; the active node holds a lock file and periodically refreshes it.
When the primary fails, the secondary waits for the lock file to become stale (TTL) and then takes over. From the client side, you should expose a single virtual endpoint (for example, a load balancer) that routes traffic only to the active node. This model requires failover logic that can switch traffic in your load balancer or reverse proxy, including solutions that support backup upstreams (for example, NGINX).
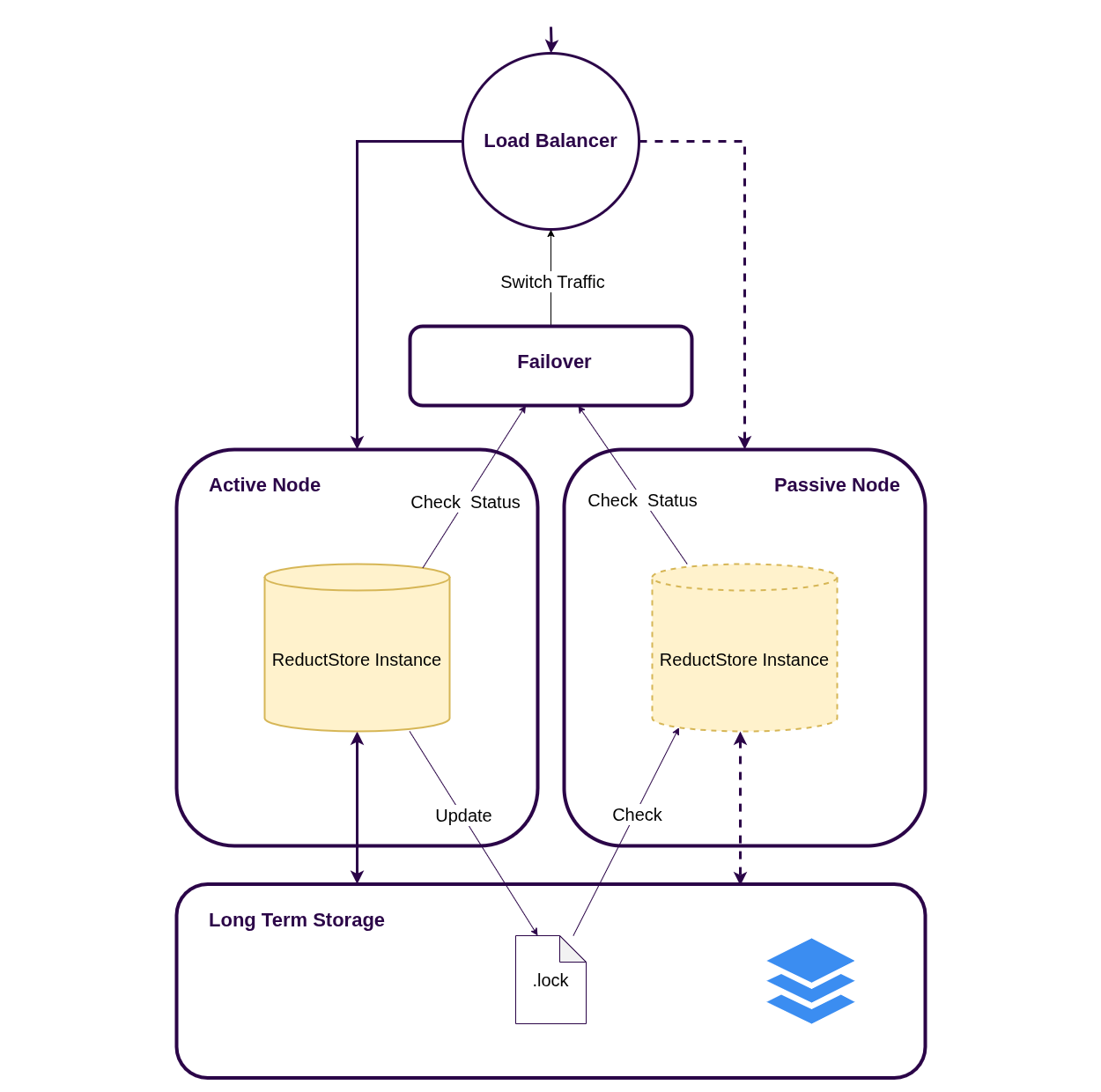
Prerequisites
- Both instances must point to the same dataset (
RS_DATA_PATHon shared storage, or the same remote backend configuration). - Use
RS_INSTANCE_ROLE=PRIMARYon the primary node andRS_INSTANCE_ROLE=SECONDARYon the standby node. - Use
GET /api/v1/alivefor a basic liveness health check. - Put both nodes behind a load balancer that checks
GET /api/v1/readyand routes traffic only to nodes returning200 OK(only the active node returns200).
Do not run two active writers on the same dataset without proper coordination. If both nodes can write at the same time (split-brain), data corruption is likely.
Make sure neither instance runs in STANDALONE mode; use RS_INSTANCE_ROLE=PRIMARY and RS_INSTANCE_ROLE=SECONDARY for hot standby.
Example: Docker Compose (shared storage)
This example shows the lock-file based active-passive setup on a shared data directory. In production, the shared storage must be accessible from both nodes (for example, NFS, EFS, CephFS).
version: "3.9"
services:
reduct-primary:
image: reduct/store:latest
environment:
RS_INSTANCE_ROLE: PRIMARY
RS_DATA_PATH: /data
RS_LOCK_FILE_TTL: 45s
RS_LOCK_FILE_TIMEOUT: 0
volumes:
- reduct-data:/data
ports:
- "8383:8383"
reduct-secondary:
image: reduct/store:latest
environment:
RS_INSTANCE_ROLE: SECONDARY
RS_DATA_PATH: /data
RS_LOCK_FILE_TTL: 45s
RS_LOCK_FILE_TIMEOUT: 0
volumes:
- reduct-data:/data
ports:
- "8384:8383"
volumes:
reduct-data:
Tuning and failover behavior
RS_LOCK_FILE_TTLcontrols how long the secondary waits before taking over after the primary stops refreshing the lock.RS_LOCK_FILE_TIMEOUTcontrols how long a node waits to acquire the lock before exiting. Use0to wait indefinitely.- For liveness health checks, use
GET /api/v1/alive. - For routing only to the active node, use
GET /api/v1/ready: the active node returns200, the standby returns503until it acquires the lock.
For an end-to-end active-passive setup on cloud storage, see Cloud Storage Integration.
Read-only Replicas
Read-only replicas let you run multiple ReductStore instances in REPLICA mode against the same dataset.
Replicas serve reads only and periodically refresh bucket metadata and indexes from the storage backend, so newly written data is not visible immediately.
This deployment pattern helps you:
- Decouple ingestion from readers: clients write to a dedicated ingestion endpoint and read from separate query endpoints
- Scale read operations horizontally by adding more replicas
- Improve read availability: if one replica goes down, others keep serving queries
Read-only replicas provide high availability for reads. To keep writes available during failures, combine replicas with Hot Standby Setup for the ingestion endpoint.
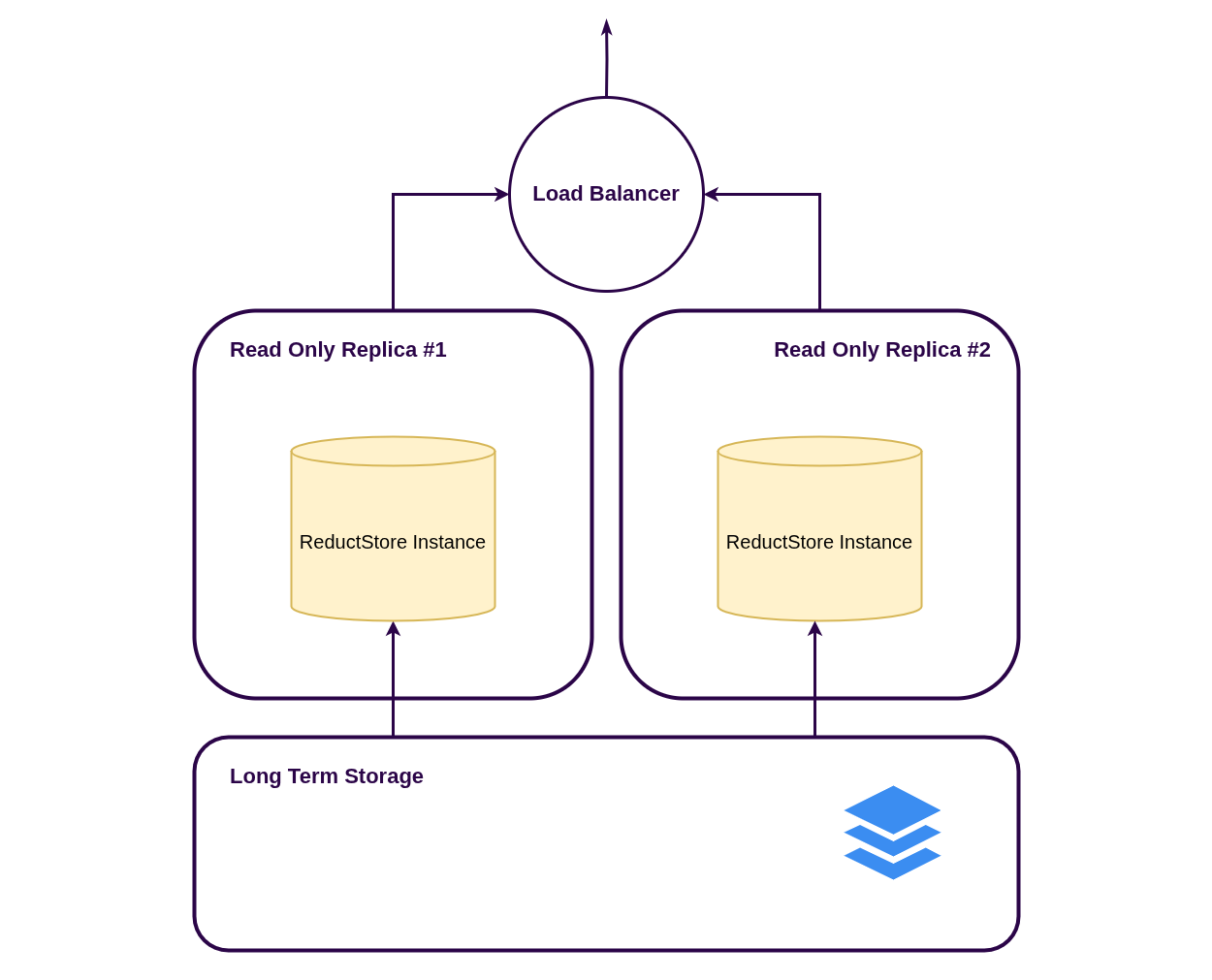
Prerequisites
- A shared storage backend that all nodes can access (for example, S3 or a shared file system).
- A writer node for ingestion (
RS_INSTANCE_ROLE=STANDALONEorRS_INSTANCE_ROLE=PRIMARY/SECONDARYif you also use hot standby). - One or more replica nodes with
RS_INSTANCE_ROLE=REPLICA.
Traffic routing
- Use
GET /api/v1/aliveas a liveness health check for replicas. - Route write traffic to the ingestion endpoint (writer node).
- Route read traffic to replicas (for example, via a separate load balancer for query traffic).
Tuning
Read-only replicas poll for metadata and index updates, so data appears with a delay. Use these variables to tune staleness:
RS_ENGINE_REPLICA_UPDATE_INTERVAL: How often replicas refresh bucket metadata and indexes from the backend.RS_ENGINE_COMPACTION_INTERVAL: How often the writer compacts WALs into blocks and syncs them to the backend (in addition to syncing when a block is finished).
Example: Docker Compose (shared storage)
This example shows one writer and two read-only replicas using the same shared data directory. In production, the shared storage must be accessible from all nodes (for example, NFS, EFS, CephFS).
version: "3.9"
services:
reduct-writer:
image: reduct/store:latest
environment:
RS_INSTANCE_ROLE: PRIMARY
RS_DATA_PATH: /data
volumes:
- reduct-data:/data
ports:
- "8383:8383"
reduct-replica-1:
image: reduct/store:latest
environment:
RS_INSTANCE_ROLE: REPLICA
RS_DATA_PATH: /data
RS_ENGINE_REPLICA_UPDATE_INTERVAL: 30s
volumes:
- reduct-data:/data
ports:
- "8384:8383"
reduct-replica-2:
image: reduct/store:latest
environment:
RS_INSTANCE_ROLE: REPLICA
RS_DATA_PATH: /data
RS_ENGINE_REPLICA_UPDATE_INTERVAL: 30s
volumes:
- reduct-data:/data
ports:
- "8385:8383"
volumes:
reduct-data:
For a full walkthrough using cloud storage, see Cloud Storage Integration.