Any Data Format
Store multimodal time series of any size: images, video, LiDAR, IMU, logs, files, ROS bags and more.
Fleet Scale Collection
Collect from many robots or devices and replicate to the cloud over intermittent connectivity.
Lower Cost at Scale
Use S3 compatible blob storage and batch records into fewer objects to reduce storage and API costs.
Best Performance
High throughput ingestion and fast retrieval of exact time ranges for replay, debugging, and training.
Developers choose ReductStore
Trusted by robotics and IIoT engineers to process billions of time-indexed records










Multimodal Time Series Storage
Store time ordered records of any type and size: log files, images, video, LiDAR, ROS bags and more.
Labels and Filtering
Attach labels to records and filter reads and replication to keep only the data you need.
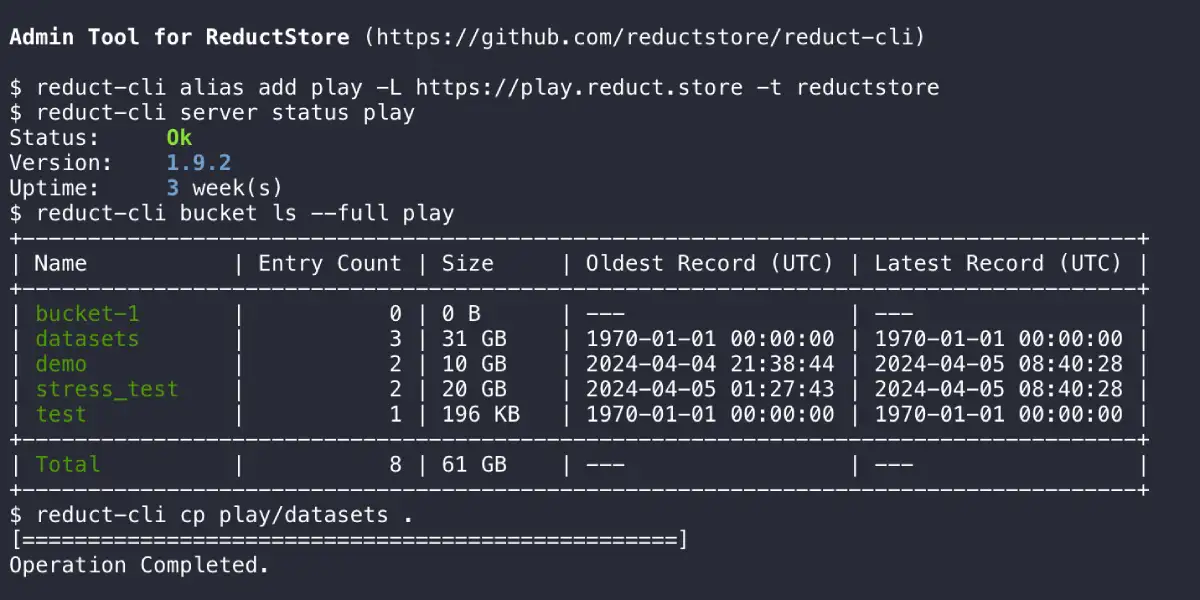
Selective Edge to Cloud Replication
Replicate using rules based on labels or events, even with limited bandwidth and intermittent connectivity.
Batching for Lower Cloud Cost
Batch records into fewer objects for S3 compatible storage to reduce API overhead and cloud cost.
No Hard Size Limits
Handle small sensor samples to large blobs like video clips, frames, point clouds, and files.
Retention and Quotas
FIFO quotas based on volume keep edge disks from filling up and maintain a rolling window of recent data.
Fast Event Retrieval
Query exact time ranges and filter by labels to replay events and debug without scanning hour long logs.
Extensible Query Engine
Use extensions to transform data during queries, like resizing images, filtering CSV, or extracting ROS topics.
Token Authorization
Secure access for devices and services with token based authorization.
- Python
- JavaScript
- Go
- C++
- Rust
- cURL
import time
import asyncio
from reduct import Client, Bucket
async def main():
client = Client('http://127.0.0.1:8383')
bucket: Bucket = await client.create_bucket("my-bucket", exist_ok=True)
ts = time.time_ns() / 1000
await bucket.write("entry-1", b"Hey!!", ts)
async with bucket.read("entry-1", ts) as record:
data = await record.read_all()
print(data)
loop = asyncio.get_event_loop()
loop.run_until_complete(main())
Client SDKs
Read and write data, attach labels, and query time ranges from your applications.
Try SDKs →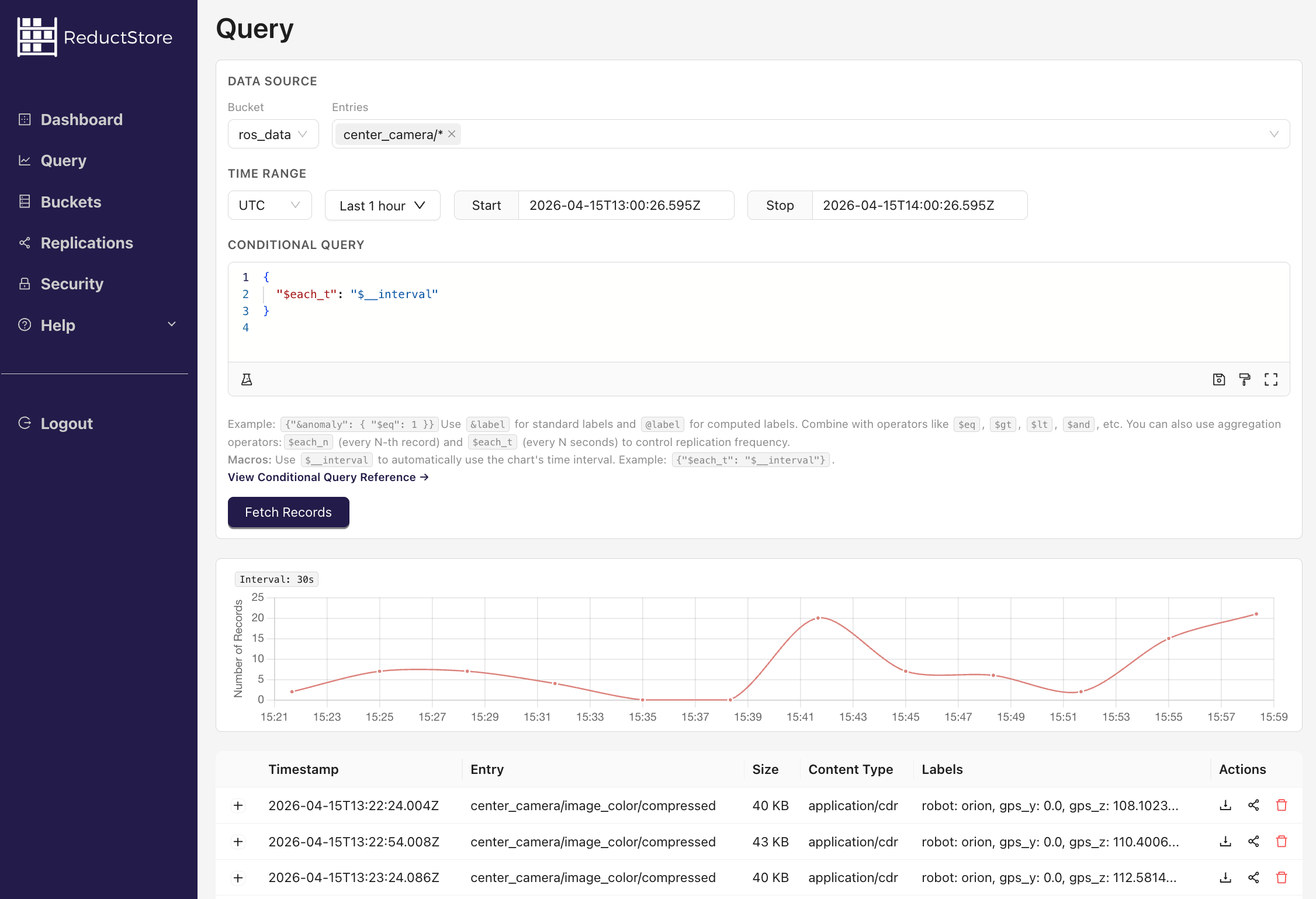
Reduct Bridge
Collect data from multiple sources, label it automatically, and store it efficiently in ReductStore with ReductBridge.
Learn More →- vs TimescaleDB
- vs MongoDB
- vs MinIO
| Record Size | Read Speed (%) | Write Speed (%) |
|---|---|---|
| 1 MB | +671% | +1604% |
| 100 KB | +603% | +924% |
| 10 KB | +313% | +297% |
| 1 KB | +28% | +198% |
High Performance
Optimized for robotics and industrial workloads. 100KB images: 10x faster writes than TimescaleDB, 16x faster reads than MinIO.
See Benchmarks →Observability
Visualize time-series data in Grafana dashboards. Query labels and content of records (e.g. CSV columns, JSON fields, ROS message fields). Set up alerts for anomalies.
Setup Grafana →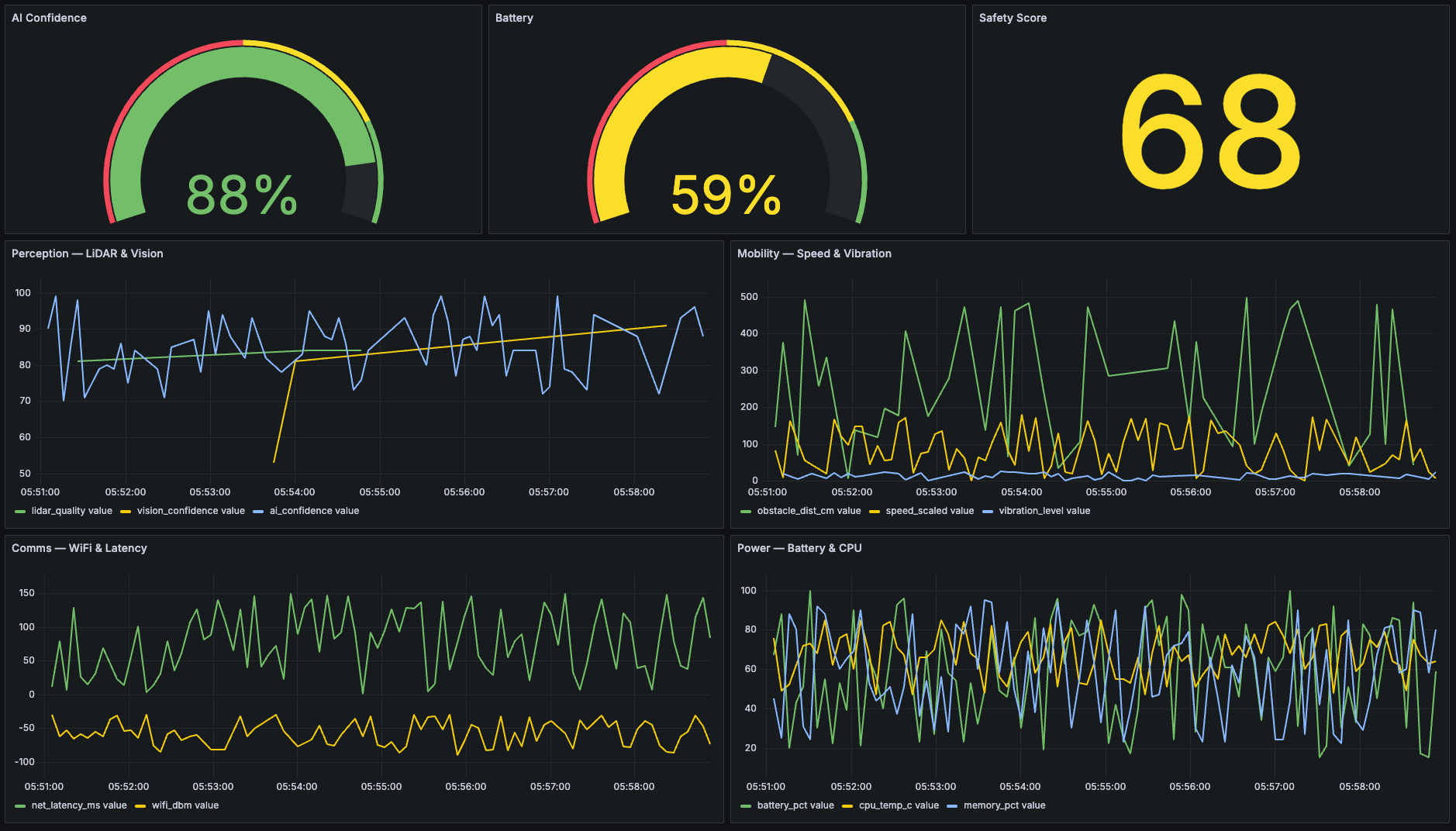
Robotics Support
ReductBridge records ROS2 topics directly to storage. Store camera feeds, LiDAR scans, and sensor data with timestamps. Foxglove for visualization and debugging.
Learn More →Typical Use Cases

Robotics Data
A database purpose built for robotics data pipelines (AMRs, drones, ROS, physical-AI systems) with practical examples.

Data Acquisition for Manufacturing
Learn how to store and manage data for edge computing and AI application in manufacturing.

Computer Vision
Explore how to implement computer vision applications in industrial settings with practical examples.

Vibration Data
Strategies for reducing and storing vibration sensor data effectively.

MQTT Data Storage
Best practices for storing and managing MQTT data in IIoT applications.

Kafka Data Sink
Learn how to set up a data sink using Apache Kafka for data streaming applications.
Frequently Asked Questions
ReductStore is a time-series database for blob data—images, sensor readings, rosbags, logs—designed for robotics and industrial applications. Store data on edge devices or robots, then replicate to on-prem servers or cloud with cloud object storage backend. Learn more in the How Does It Work section.
Set up replication tasks to stream data from edge devices to another instance—on-prem or cloud. Supports high availability setups and S3 backends for cloud deployments. See the Cloud Storage Integration guide.
Self-managed with ReductStore Core, self-hosted with ReductStore Pro, or managed cloud on our infrastructure. Core and Pro share the same storage engine, while Pro adds commercial components and support. Check our Pricing page for details.
Time-Series Blob Storage for Robotics & Industrial IoT
Learn how ReductStore helps robotics and industrial teams store images, sensor data, and logs on edge devices, then replicate to on-prem or cloud. With benchmarks and comparisons vs. TimescaleDB, MongoDB, and MinIO.
Download White Paper (PDF)