How to Store Vibration Sensor Data

This is a complete guide to storing vibration sensor data efficiently and effectively. We'll cover everything from the basics of vibration data to best practices for managing it as well as setting up a robust and scalable environment to store, query, and replicate vibration sensor data.
Vibration data is typically collected from sensors attached to machinery or equipment to monitor its health and performance. This data can be used to detect anomalies, predict failures, and optimize maintenance schedules.
However, effectively managing vibration data can be challenging due to its high frequency, large volume, and complex nature. To address these challenges, we must implement efficient storage strategies that balance data retention with storage constraints.
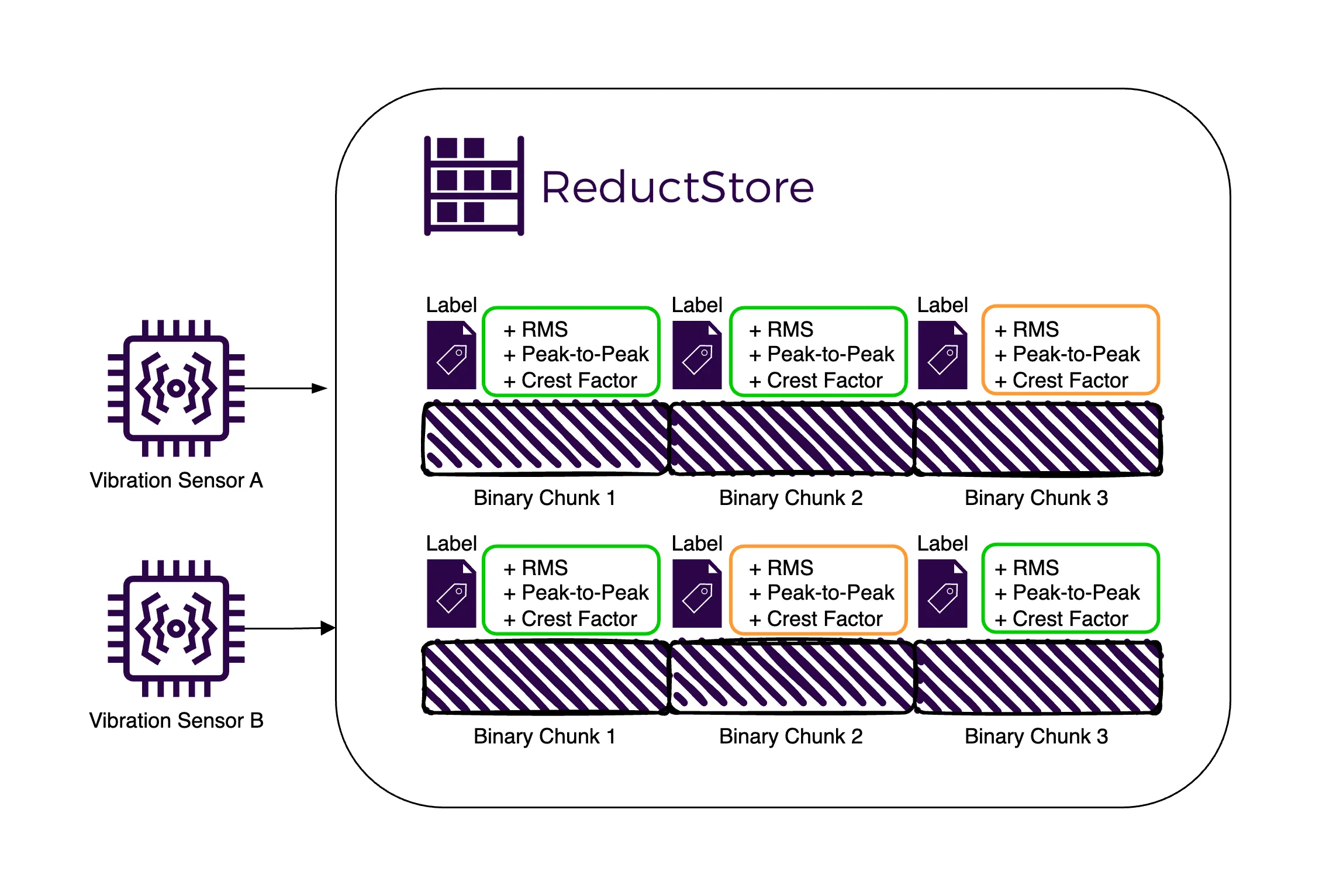
After covering the basics of vibration data, we'll explore the best practices for managing this data, including storing both raw and pre-processed metrics to take advantage of their benefits. We'll also look at the differences between traditional time series databases and a time series object store such as ReductStore, which is designed to efficiently handle time series unstructured data, making it an excellent choice for storing high-frequency vibration sensor measurements.
We'll then cover a real-world example of storing vibration sensor data using Python and ReductStore. This example will show you step-by-step how to store raw sensor data, calculate key metrics, and query and retrieve this data for analysis.
Finally, we'll discuss strategies for preventing data loss through volume-based retention policies and automated replication to ensure that valuable information is always available for diagnosis and analysis.