How to Find the Best Pre-Trained Models for Image Classification

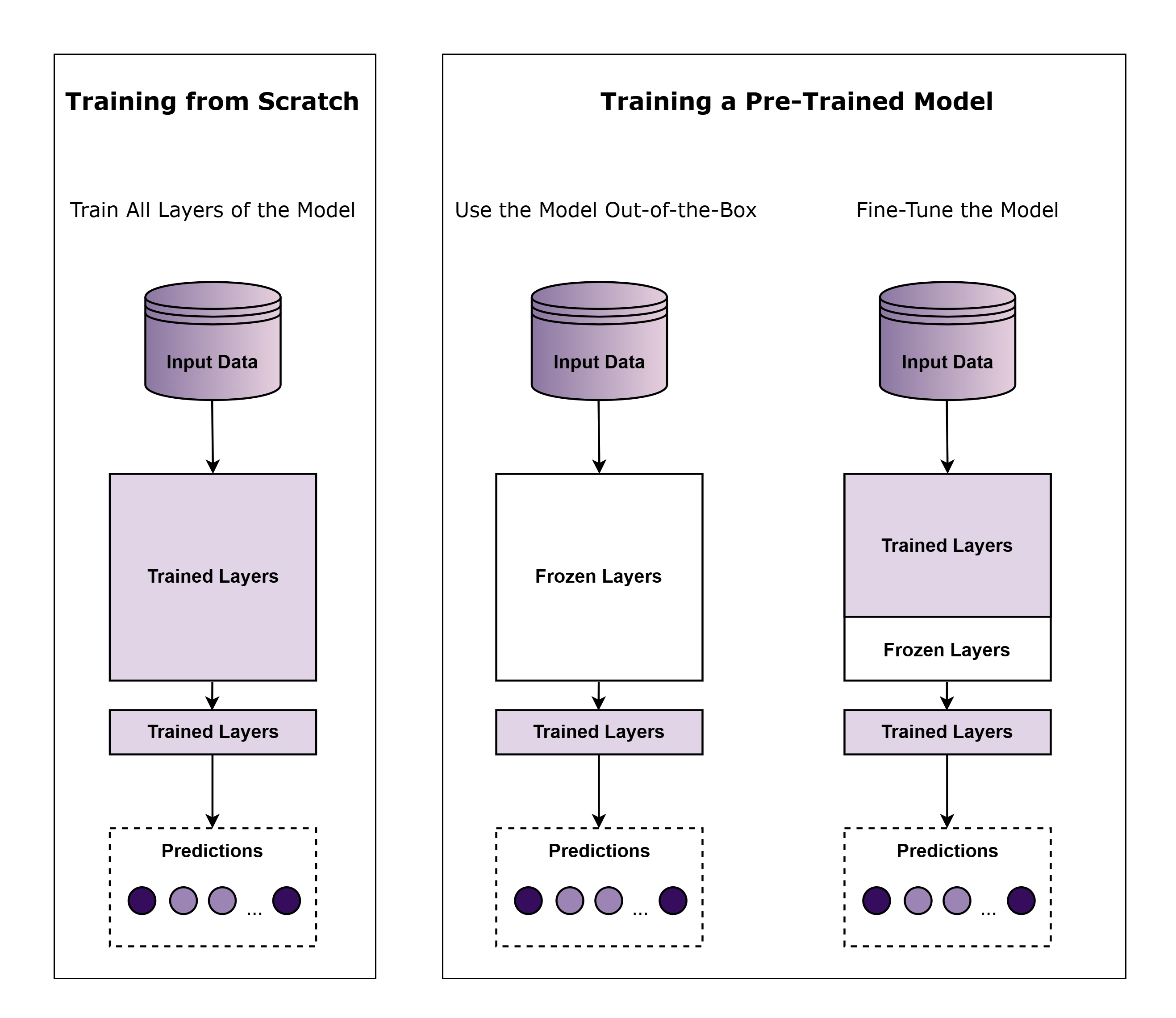
A pre-trained model is a neural network that has already been trained on a large dataset to perform specific tasks, such as image classification or object detection. These models are highly valuable, allowing us to build on previous knowledge rather than starting from scratch.
However, computer vision models often require large datasets of labeled images or videos, which can quickly become challenging to manage, especially when sourced from continuous data streams. ReductStore addresses this need by providing an efficient and reliable time-series object store capable of handling large volumes of high-frequency, unstructured data such as video streams or labeled images. For practical guidance on implementing ReductStore and integrating it with Roboflow to develop high-performing computer vision models, refer to the guide: Computer Vision Made Simple with ReductStore and Roboflow.
Here's what we'll cover in this article:
- Why Use Pre-Trained Models for Image Classification?
- Key Criteria for Choosing a Pre-Trained Model
- Top Resources for Finding Pre-Trained Models in Image Classification
- Fine-Tune a Pre-Trained Model with Roboflow
- Best Practices
Why Use Pre-Trained Models for Image Classification?
Training computer vision models from scratch presents several significant challenges that can impact project timelines and budget allocations. Firstly, the process demands extensive computational resources and high-performing GPUs, which can be expensive to access and maintain. Additionally, it requires massive labeled datasets - often hundreds of thousands of images and videos - which are time-consuming and expensive to collect, clean, and annotate.
When training from scratch, the process itself can extend to weeks or even months, depending on the model's complexity and dataset size, with no guarantee of achieving desired accuracy levels. Lastly, developing and training models from scratch involves complex architectural decisions and hyperparameter tuning, requiring in-depth technical knowledge of the domain.
Pre-trained models address these challenges through transfer learning, and the key benefits include:
- Resource Efficiency: Minimizes computational and data requirements through existing learned parameters, reducing both infrastructure costs and data collection efforts.
- Robust Feature Learning: Uses advanced feature representations learned from large and diverse datasets, providing better initial performance and more stable learning dynamics.
- Reduced Development Time: Significantly reduces implementation time from weeks to days or even hours.
- Better Generalization: Provides more robust performance across multiple scenarios compared to models trained on limited datasets due to broad exposure to different patterns and features during pre-training.
- Proven Architecture: Benefits from architectures that have been tested and validated by the research community, reducing the risk of structural issues and optimization problems.
Key Criteria for Choosing a Pre-Trained Model
When selecting a pre-trained model for image classification, several critical considerations come into play:
- Model Accuracy: While accuracy serves as the primary metric due to its simplicity, it shouldn't be the only determining factor. Precision, recall, and F1 scores offer deeper insights into model performance, especially with imbalanced datasets. Not to mention the mAP (mean Average Precision) metric, which is particularly useful for object detection tasks.
- Model Architecture Complexity: The complexity of the model is also a deciding factor when it comes to choosing a pre-trained model, particularly in edge deployment scenarios. While deeper networks with a lot of convolutional and dense layers might achieve better accuracy, they often come with significant computational overhead. A model with millions of parameters may be great in a cloud environment, but impractical for edge devices with limited processing power and memory constraints. For edge applications in particular, we should consider processing times, model size and power consumption in addition to performance metrics.
- Accessibility and compatibility: Different models may have varying levels of compatibility with frameworks, programming languages, and runtime environments, which can significantly impact implementation timelines and development complexity.
Top Resources for Finding Pre-Trained Models in Image Classification
There are so many available that finding pre-trained models can be overwhelming, but several platforms have proven to be useful resources for finding and implementing state-of-the-art image classification models. You can find a summarized version of my go to platforms in the table below:
| Platform | Overview | Key Features | Implementation Example |
|---|---|---|---|
| PapersWithCode | A research-focused platform that closes the gap between academic work and practical implementation. |
| Find top-performing models for specific tasks, such as facial recognition, by filtering benchmarks and accessing implementation code directly through linked repositories. |
| Roboflow Universe | A broad computer vision platform that focuses on practical applications and provides end-to-end solutions. |
| Access pre-trained models for anomaly detection in manufacturing, with deployment guidelines and sample applications |
| Hugging Face | A hub for transformers and ML models, known for its extensive model repository and active community support. |
| Find highly specialized models, such as bird species identification, with exhaustive performance metrics. |
| Kaggle | A competitive data science platform that hosts competitions and serves as a repository for collaborative notebooks |
| Learn new approaches and customize notebooks for your own data sets. |
| TensorFlow Hub | Google's official model repository for TensorFlow, dedicated to production-ready models. |
| Deploy efficient models for mobile applications with minimal setup. |
| PyTorch Hub | Meta's official model repository for PyTorch, featuring research-oriented implementations and seamless integration with PyTorch. |
| Implement complex architectures with detailed examples and performance guidelines. |
Fine-Tune a Pre-Trained Model with Roboflow
In this section, we'll walk you through the process of fine-tuning a model for the ‘rock-paper-scissors' object detection task in Roboflow. This example will focus on dataset preparation, model selection, model training, fine-tuning, and deployment. Please note that for the sake of simplicity, we will be using an already labeled dataset that is publicly available on Roboflow. If you are in need of an efficient data management solution, consider exploring ReductStore as a solution to optimize edge-to-cloud image storage.
Preparing the Dataset
The first step of the training process is to find a suitable dataset. You can either create and label your own dataset from scratch or, more conveniently, find a pre-existing one on platforms like Kaggle and Roboflow Universe. For this example, we'll use a labeled dataset of over 7,000 images provided by the previously mentioned rock-paper-scissors project.
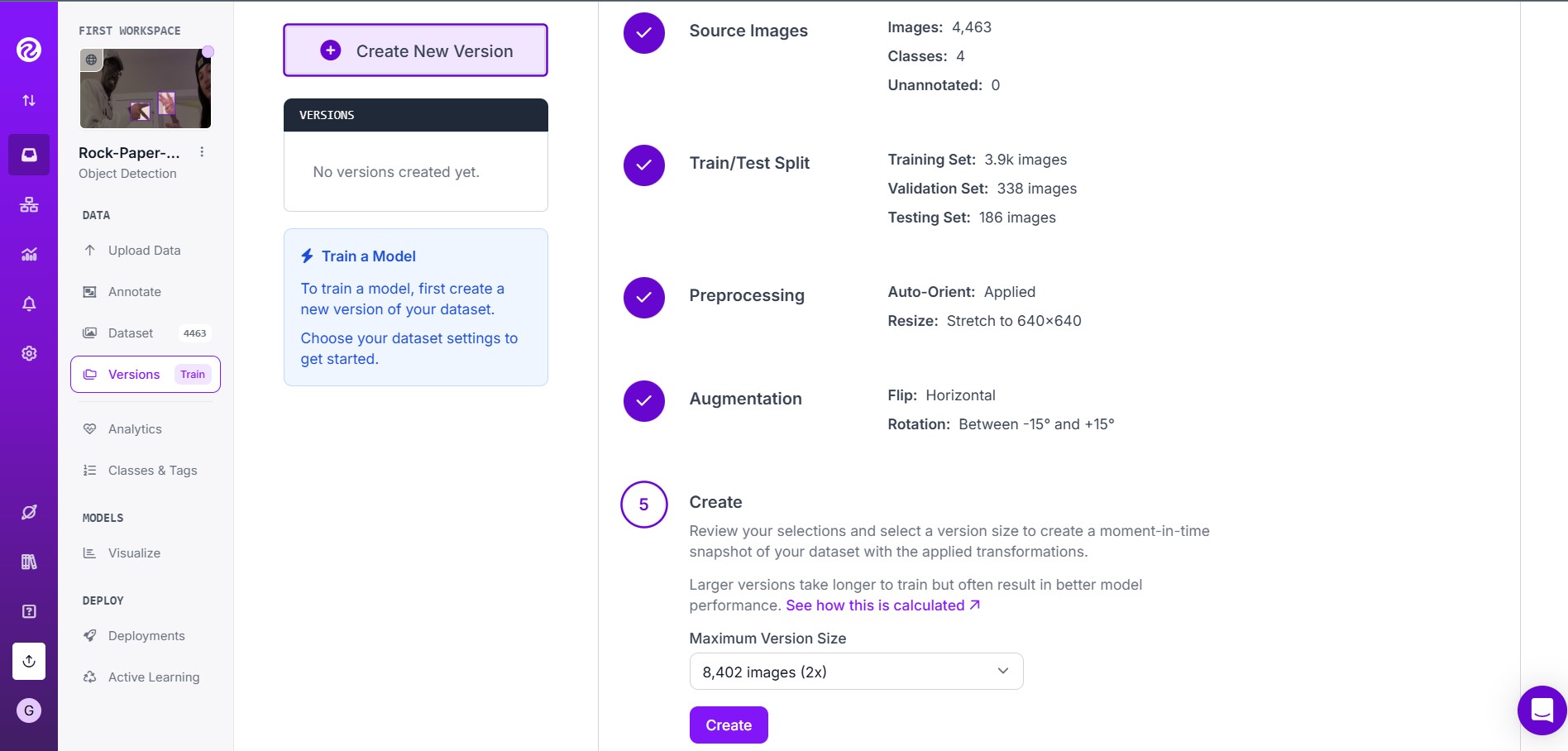
In your Roboflow workspace project dashboard, navigate to the Versions tab to create a new, modified dataset version. Here, you can adjust the train/validation/test split ratios, apply preprocessing steps, and enable augmentations such as rotation, brightness adjustments, and cropping to improve the model's robustness.
Model Selection
Finding an appropriate model for the task requires some research on the platforms discussed in the previous section, but we should also look at model accuracy, hardware limitations, and latency requirements as discussed in the Computer Vision Made Simple with ReductStore and Roboflow (Model Selection Criteria).
In our case, after exploring various options, we found a project on Kaggle, Rock Paper Scissors Detection using YOLOV11, which showed that YOLOv11 could perform very well on such a task, so we decided to proceed with this model as our pre-trained model of choice.
Fine-tuning and Training the Model
With the model selected and the dataset prepared, we can move on to fine-tuning and training the model. The initial setup includes installing the necessary packages, authenticating with Roboflow, and downloading the dataset. Here is an example from a Jupyter Notebook available in the reduct-roboflow-example repository:
!mkdir {HOME}/datasets
%cd {HOME}/datasets
!pip install roboflow
from roboflow import Roboflow
api_key = "<YOUR_API_KEY>"
workspace = "<YOUR_WORKSPACE>"
project = "<YOUR_PROJECT>"
rf = Roboflow(api_key=api_key)
project = rf.workspace(workspace).project(project)
version = project.version(1)
dataset = version.download("yolov11")
Now, to fine-tune YOLOv11's model, you need to adjust training settings (hyperparameters) such as learning rate, batch size, image resolution, and number of epochs to get the best results. There's no set formula for choosing the best values for these settings-you usually have to try different combinations and see what works best. You can do this by trial and error, or by automatically exploring combinations using methods such as random or grid search.
!yolo task=detect mode=train model=yolo11s.pt data={dataset.location}/data.yaml lr0=0.01 batch=16 epochs=100 imgsz=640 plots=True
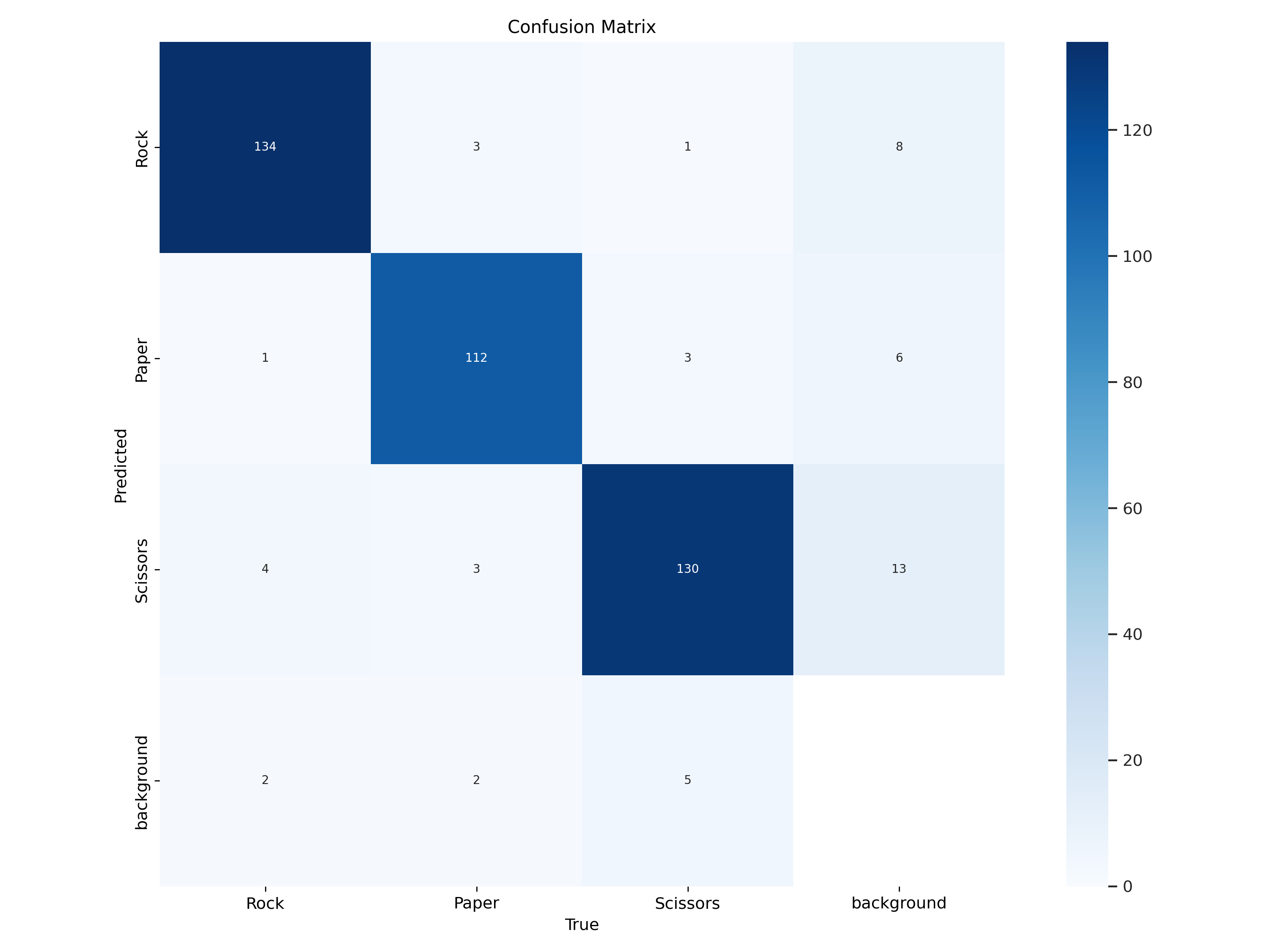
This command initiates model training, and when it's complete, you'll have access to several performance metrics, including accuracy, loss, and a confusion matrix, which provides insight into the model's performance. Here's the confusion matrix we got after training the YOLOv11 model:
Deployment
Once training is complete, you can deploy your fine-tuned YOLOv11 model to Roboflow with the following command:
!project.version(dataset.version).deploy(model_type="yolov11", model_path=f"{HOME}/runs/detect/train/")
After uploading the model, go to the Deployment tab in your Roboflow project to access your custom-trained model. You can use this model for inference either in the cloud or for edge deployment depending on your specific requirements.
Best Practices
Here are some best practices to maintain model performance and data quality over time:
- Select appropriate evaluation metrics: It is important to monitor general accuracy metrics such as overall accuracy, precision, recall, mAP, as well as operational performance metrics such as inference time, model size, and resource usage.
- Implement continuous monitoring: Regularly tracking model performance is the only way to detect degradation in accuracy over time. You can monitor confidence levels across classes and look for "patterns" of misclassification.
- Use an efficient data storage system: A robust data storage solution keeps your training samples organized and easy to retrieve, helping you quickly update and maintain models. Solutions like ReductStore are designed specifically for this purpose, making data handling smoother and more effective.
Conclusion
Pre-trained models have truly changed the way we approach image classification and provide a foundation for custom applications. We can all speed up the way we develop models by using platforms like Roboflow and by using pre-trained models from Hugging Face, TensorFlow Hub or PyTorch Hub. Not to mention Kaggle and PapersWithCode, which are also great resources for finding the latest research and implementations.
One aspect that can be overlooked is the storage infrastructure that must be in place to store images and inference labels at the edge and in the cloud. ReductStore's specialized capabilities provide the necessary infrastructure to handle billions of time-stamped images with AI labels.
In closing, I'd like to encourage you to take the next step in your computer vision journey by exploring the above platforms to find the perfect state-of-the-art pre-trained model for your specific use case, and consider implementing a robust data management solution like ReductStore to complement your AI infrastructure.
Thanks for reading. If you have any questions or comments, feel free to use the ReductStore Community Forum.