Data Acquisition System for Manufacturing: Shop Floor to Cloud
· 7 min read

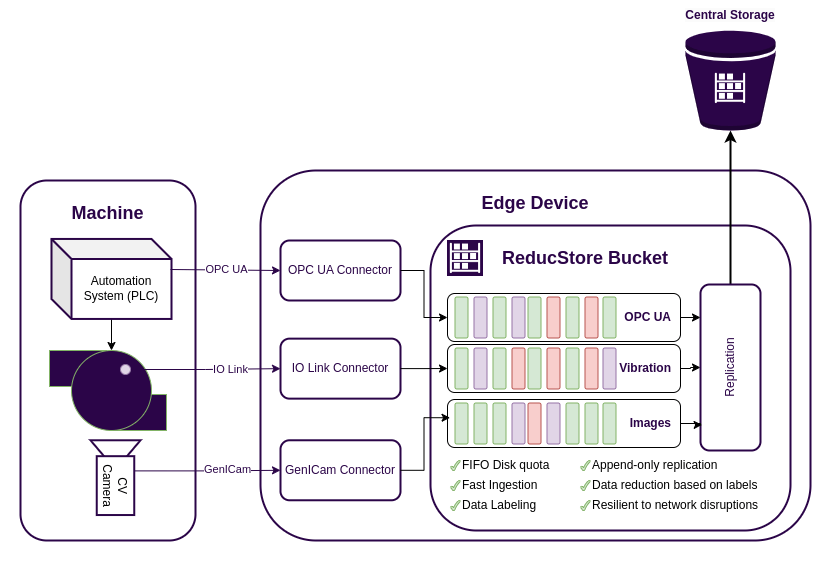
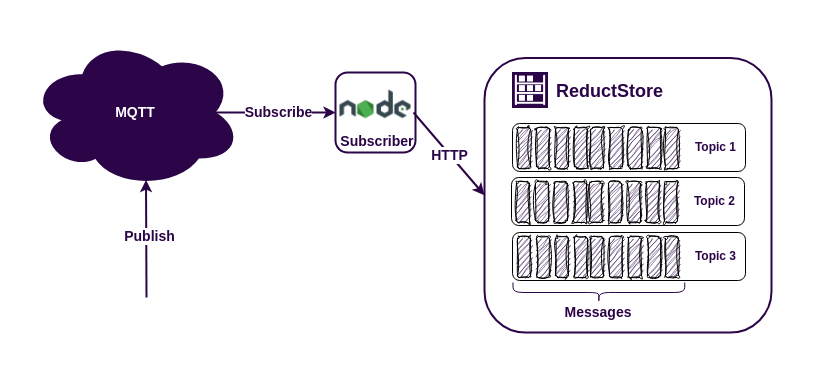
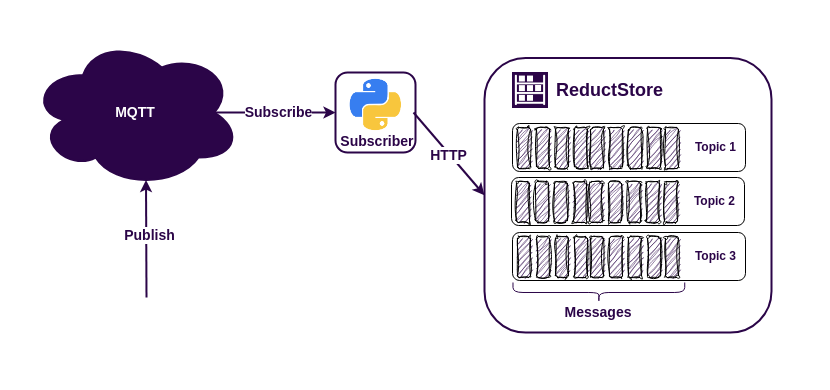
As modern manufacturing becomes increasingly data-driven, the need for efficient data acquisition systems is more critical than ever. In my previous article, Building a Data Acquisition System for Manufacturing, we discussed the challenges of data acquisition in manufacturing and how ReductStore can help solve them. Here we will learn how to use ReductStore at the edge of the shop floor and stream data to the cloud.