Release v1.8.0: Introducing Data Replication

We are pleased to announce the release of the latest minor version of ReductStore, 1.8.0. ReductStore is a time series database designed for storing and managing large amounts of blob data.
To download the latest released version, please visit our Download Page.
What's New in ReductStore v1.8.0
In this release, we're introducing a crucial feature for any database - data replication. Now, you can create a server-side task that "subscribes" to new records written to a bucket and forwards them to another bucket. This bucket can be located on the same instance or a remote one. Since all databases implement replication differently based on their specializations, let's examine how ReductStore tackles this.
Replication in ReductStore
Append-Only Approach
Currently, replication is append-only, meaning we only synchronize new records when they are written but not deleted or update. As ReductStore is typically used as an efficient FIFO buffer for blob data, it automatically removes old data when the disk quota is exceeded. Therefore, it doesn't make sense to replicate the remove operation on a remote instance where the disk space might be different.
Edge/IoT Optimization
Our goal is to create a storage solution tailored for IoT and Edge computing, and this consideration influenced our approach to replication.
ReductStore's replication uses a transaction log to persistently store record IDs for replication. If a remote instance is unavailable, the database retains these records in its logs. This method allows for later synchronization when the remote instance is restored.
Since an IoT device may not always have a public IP for various reasons, ReductStore implements a "push" model. In this model, a source instance writes data to a destination instance, eliminating the need for direct access to the source device.
Conditional Replication
ReductStore does more than just mirror data; it also provides conditions based on labels to filter data before sending it to another instance. This type of data reduction helps reduce traffic and extend storage time for important data. For example, you can label records as "anomalous" and replicate only those records to a remote instance.
Typical Use Cases
Replication is a powerful feature that can be used in many ways. However, let's briefly discuss two scenarios where replication can help simplify your application.
Local Replication
In this use case, we have a computer vision application that detects product anomalies using images from a CV camera. The detection algorithm labels images as good or anomalous and stores them in the data bucket. We receive a few images per second, and the disk space is only sufficient to store a few days' worth of data. This amounts to a lot of images, and we would like to improve or validate our model with anomalous images. Unfortunately, anomalies occur very rarely, and we can't collect enough anomalous images in our storage time window.
This is a perfect case for replication. We can create an additional bucket with a small quota and replicate only the anomalous images there. Depending on the quota chosen, it may store a few months' worth of data, which could be sufficient for our purposes.
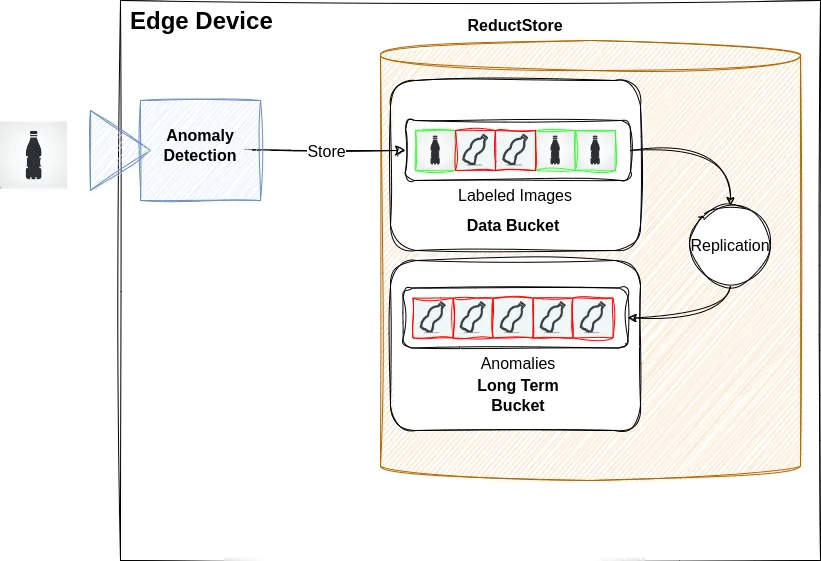
Remote Replication
We could address this by setting up a server with a ReductStore database in our infrastructure and replicating the anomalous images from the edge device to the server.
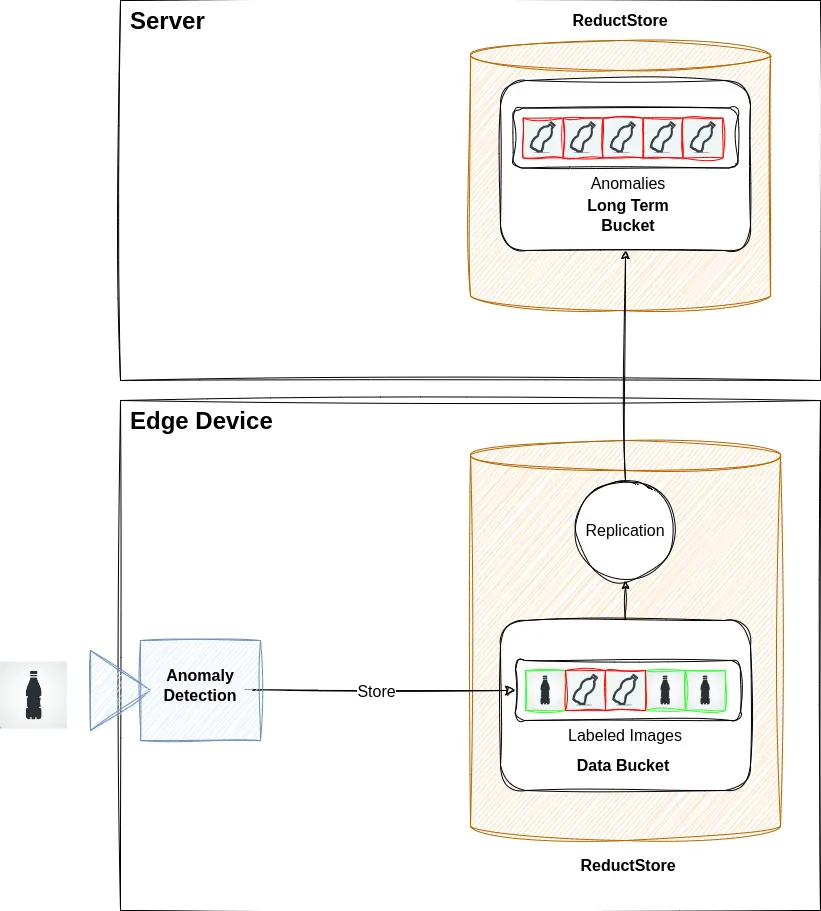
Configuration
You can establish replications using the HTTP API or provision it with environment variables. Instead of using the HTTP request directly, we recommend using our client SDKs.
We will soon update ReductCLI and Web Console to offer a convenient method for monitoring and managing replications.
I hope you find this release useful. If you have any questions or feedback, don’t hesitate to use the ReductStore Community forum. Thanks for using ReductStore!