Implementing Data Streaming in PyTorch from Remote DB
· 9 min read

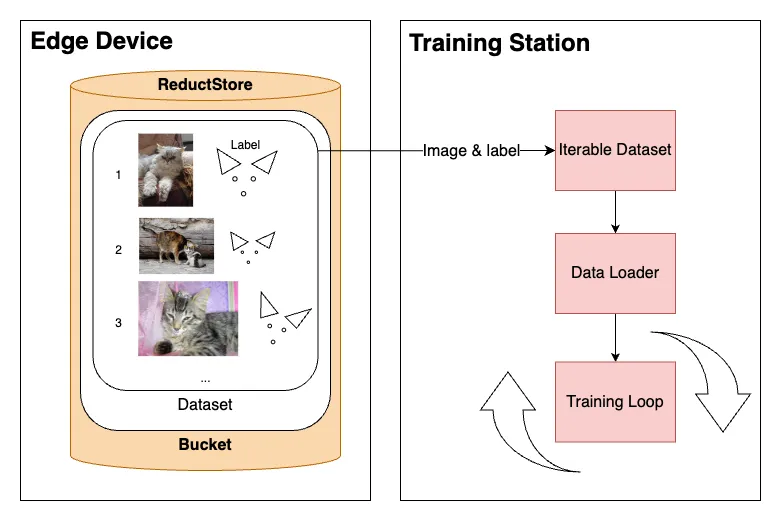
When training a model, we aim to process data in batches, shuffle data at each epoch to avoid over fitting, and leverage Python's multiprocessing for data fetching through multiple workers.
The reason that we want to use multiple workers is that GPUs are capable of handling large amounts of data concurrently; however, the bottleneck often lies in the time-consuming task of loading this data into the system.
Moreover, the challenge is even trickier when there is simply too much data to store the whole dataset on disk and we need to stream data from a remote database such as ReductStore.
In this blog post, we will go through a full example and setup a data stream to PyTorch from a playground dataset on a remote database.
Let's dig in!

 Photo by
Photo by