Comparing Robotics Visualization Tools: RViz, Foxglove, Rerun
· 24 min read


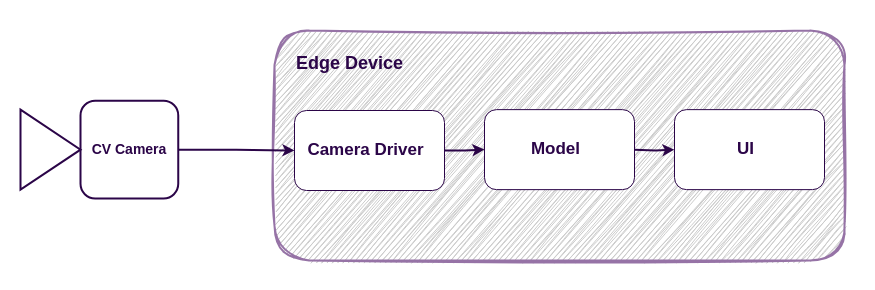
In robotics development, effective visualization and analysis tools are essential for monitoring, debugging, and interpreting complex sensor data. Platforms like RViz, Foxglove, and Rerun play a key role at the visualization layer of the observability stack. They help developers interact with both live and recorded data. These tools rely on timely, well-structured access to the underlying data streams. That's where ReductStore comes in. It handles the data logging, storage, and processing, with a focus on capturing high-volume time-series data efficiently. ReductStore aims to integrate with tools like RViz, Foxglove, and Rerun, supporting a complete observability pipeline: from raw data ingestion to actionable insights.