Visualize Robotics Data in Grafana with ReductStore
· 5 min read

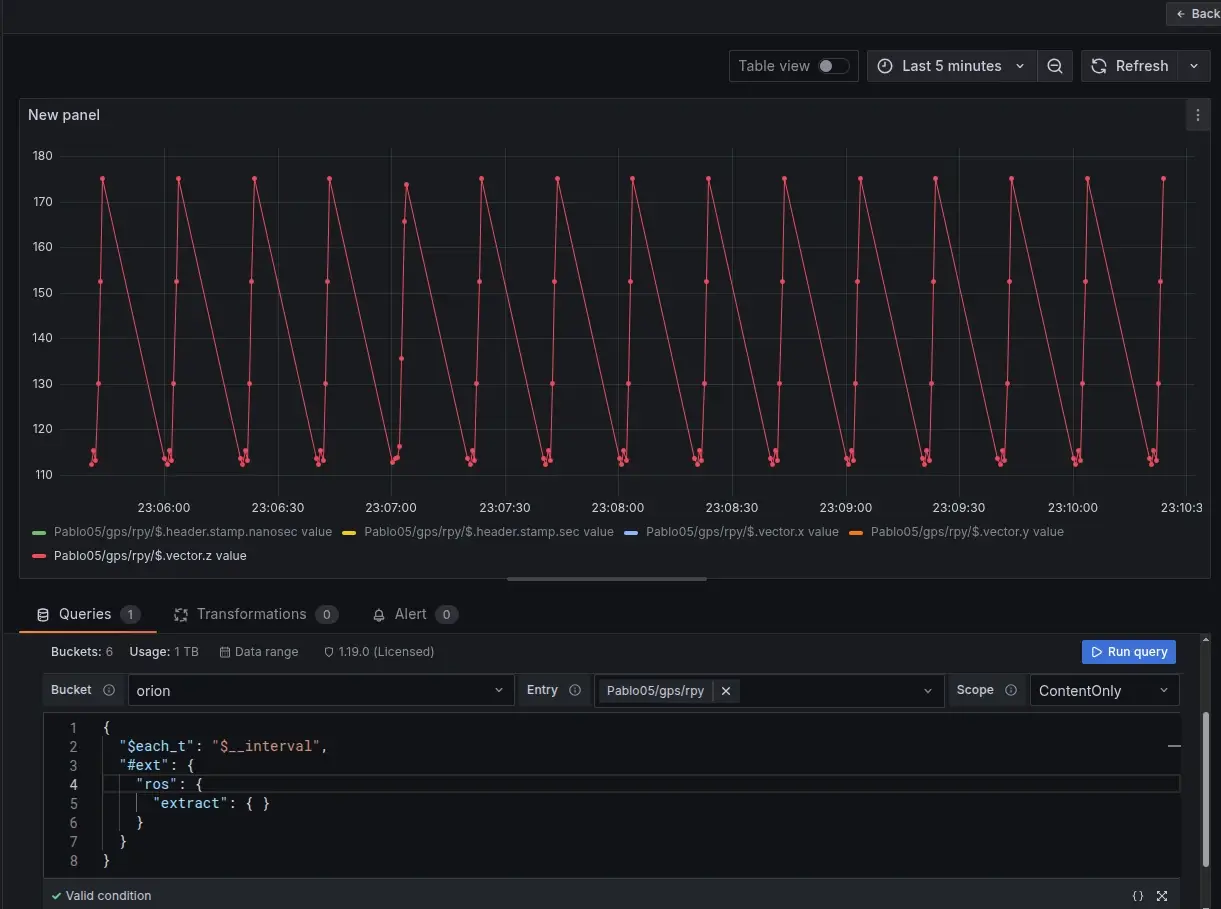
Grafana is a powerful tool for visualizing time-series data, and it is widely used for monitoring and analysis. However, it does not natively understand robotics data formats, such as ROS 2 messages, since they are usually stored in binary formats (e.g., CDR). ReductStore's flexible query engine and extension system can bridge this gap. With the ReductROS extension, you can extract ROS 2 messages as JSON directly in Grafana queries. This enables you to build rich dashboards and alerts on your robotics data without preprocessing it into a different format.